
Major issues and my solution
Previously, loading all the HTML and non-HTML data into the database has always been a headache for me. The main reason is the old database design.
Old design
The DocumentArk with darker green means it contains the actual HTML file, while ones with the lighter green means they do not contain the HTML file. You need to look into previous one for the HTML file. The LogScraper and Document defines one DocumentArk together. If there is an empty spot of the intersection, it means the web page disappeared during that day, and no HTML is yielded from that scraping task.
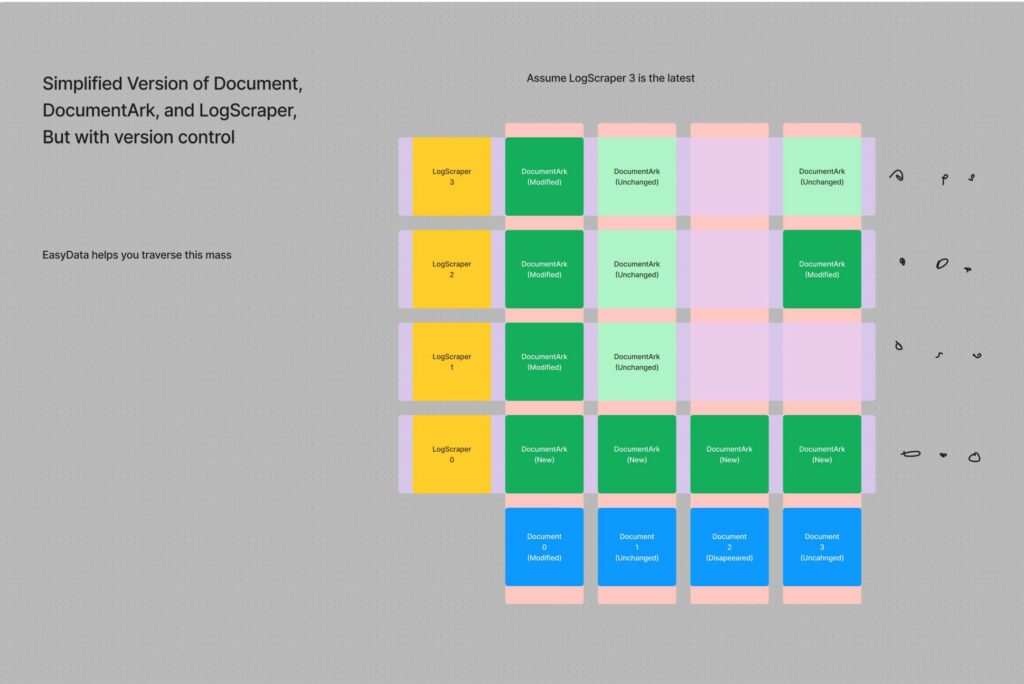
The main problem of the database design happens at version control and locating the latest HTML in the database. For example, when we need to locate the latest HTML file of Document 1, we first will find the latest LogScraper, i.e., LogScraper 3. However, in this case, the corresponding DocumentArk does not have the actual HTML file, instead, it only has one label, saying it is unchanged. Then, we will need to go through all the previous LogScraper so that we could find the first DocumentArk that is either labeled *”New”*, or *”modified”* to find the actual HTML file. Moreover, for version control, this database design is a nightmare for updating the page status tag (i.e., *new, modified, unchanged*). For an insert operation of LogScraper, let’s say, a LogScraper 4 in between 1, and 2, we would need to update all the page status tag information of newer DocumentArk. It is a nightmare to code and deal with corner cases.
New design
To solve the problem of version control and locating latest HTML pages, I redesigned the database schema. The new design removed the hated page status tags to avoid manual version control in the first place and solved the problem of needing to traverse LogScraper to find the actual HTML by giving every LogScraper-Document pair a DocumentMiddleware, which unlike the DocumentArk in previous design, does not have any place for the actual HTML file, instead it has a ForeignRelationship to DocumentArk that is different from the old one. The new DocumentArk still stores HTML file, but in addition, it stores an ForeignRelation to the Document, and a hash_id, implemented using MD5 algorithm. By using two identifications (hash_id, and ForeignRelation), there would be a very low chance for hash collision even when database grows bigger. In general, the new design guarantee that every DocumentMiddleware can have an actual HTML file only one step away, while not storing redundant information of HTML pages. In practice, *this new design allows me to load new scraped data in whatever order I like using very little code*. Very important.
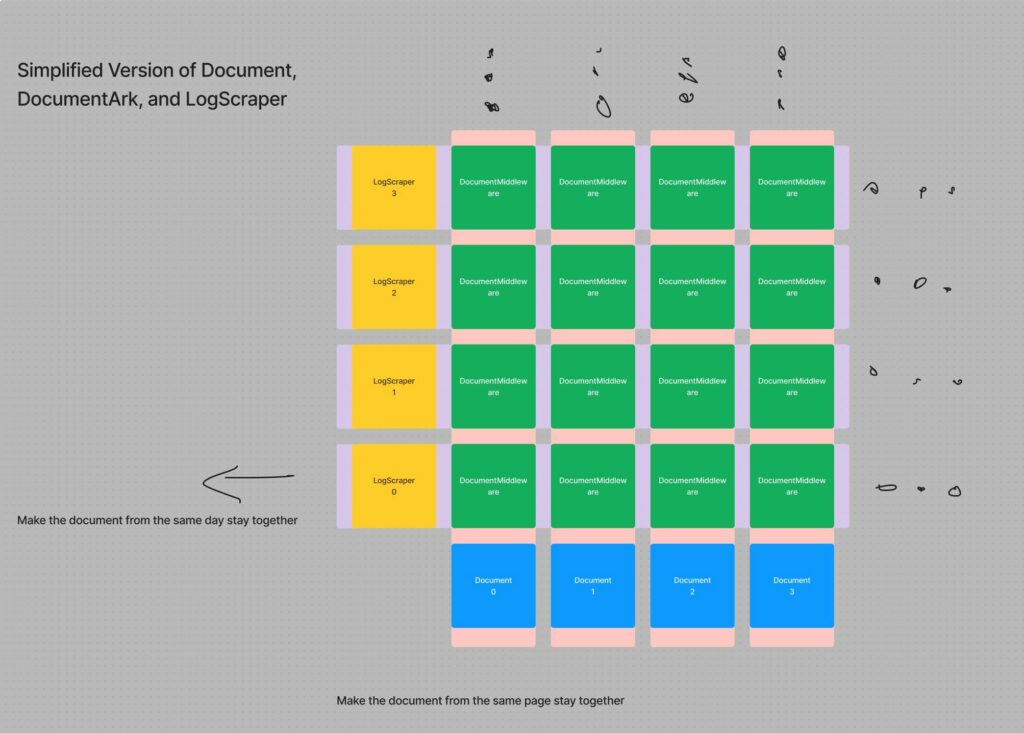
A typo is made at the top left corner. It should be DocumentMiddleware instead of DocumentArk.
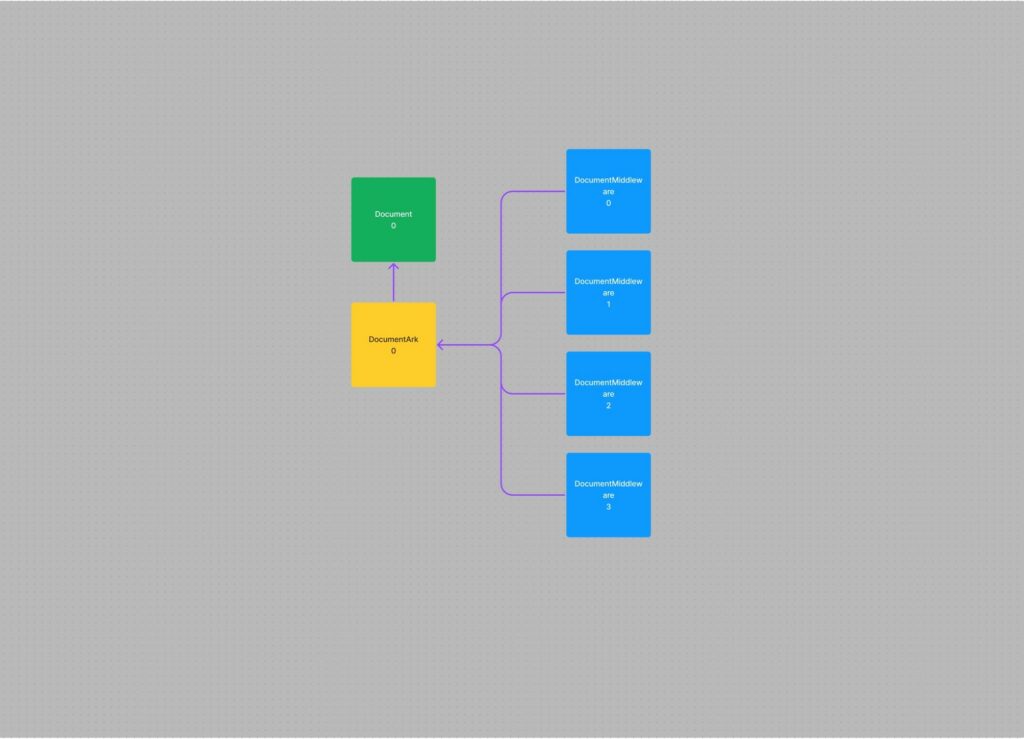
An example of the relationship between DocumentMiddleware, Document, and DocumentArk.
Summary
- Do design the database with the ease of the use in mind.
- The record batch should be consistent. Each of its key should return the same type of the content as expected.
- Do not design the database with the fetching cost of O(n). That is, page status tag system is a bad design.
- Adding additional partially redundant information may be helpful. Hash info may come handy if more document needs to be compared, because they same computational power.
Current project status, and random little things
We recruited Boen, Beilong, Echchabi, and Jay into our development group. Now the coding team was in total 6 people, as the responsibility of Jay was mainly about wrestling with Dii. Despite being a quite large group, there are only actually three people ready to contribute directly to the Webapp, and Processor part of the Search So search engine. Considering the amount of feature, we want to make, it is still a bit of stretch.
I helped Boen with setting up the coding environment on his PC. It is frustrating. The PC did not cooperate with us. First, it refused to install WSL or Ubuntu, and spit out an error code and random gibberish. I assumed the gibberish was because of Microsoft does not like Chinese, and do not want to render English properly in Chinese machines. It may be fixed by switch the language to English. The error code yielded no meaningful results in Baidu search, and it took me some time to find a proper guide on Google. It was, of course, because of some virtualization options were not enabled. I checked BIOS of his PC. TBH, Lenovo has one of the worst BIOS designs. The vanilla grey and blue ones would better than that brain-dead design of Lenovo did. Lenovo also, very cleverly, bounded the SR-IOV and IOMMU with some security features into one single option in the BIOS. Basically, it means that by enabling those security features, you might brick the boot drive. Finally, we discovered that the root course of WSL not installing is because the Windows did not by default, install the Hyper-V kit, which in my opinion, might be the best thing that they have brought to us in the last decade, and they did not include it by default. Thanks, Microsoft! Thanks, Lenovo!
After we installed the WSL, Boen still could not properly push/pull from the git repository, because of SSH key issue. After quick Googling, I figured out how to add existing SSH key into the SSH-Agent. Then, things went south even further. THE WSL WILL LOSE SSH KEY EVERY TIME IT REBOOTS! This seemed to be a bug that have existed for several years. A quick fix was to write some bash script so that every time we open a terminal, it would load the SSH key. It was a dirty and temporary solution. But it got the job done.
Proposal for next week
- I do not know.
- Dense Retrieval System?
No deposit bonus from https://zkasin0.site connect your wallet and enter promo code [3wedfW234] and get 0.7 eth + 100 free spins, Withdrawal without limits
промокод при регистрации 1xbet https://www.minoxidilspray.com/articles/promokod_260.html
К 5-летию свадьбы решил подарить жене нечто особенное – букет из искусственных цветов. Заказал его на “Цветов.ру” и добавил легкости и веселья в нашу гармоничную жизнь. Спасибо за творческий подход! Советую! Вот ссылка https://krasnodar-renault.ru/grozny/ – букет
1xbet при регистрации промокод http://braille.ru/wp-content/pgs/besplatnuy_promokod_pri_registracii.html
Недавно мне понадобилось 6 000 рублей на покупку техники. В инстаграме я узнал о yelbox.ru. На сайте представлена информация о том, как безопасно взять займы онлайн и перечень проверенных МФО. К моему удивлению, некоторые из них предлагают займы без процентов!
Instagram порой дарит неожиданные сюрпризы. Один из них – сайт wikzaim, где я нашел займы под 0%. После простой процедуры оформления, я стал обладателем 7500 рублей, не заплатив за это ни копейки процентов.
Встречайте удивительный мир комфорта и гостеприимства в отелях Туапсе! Погрузитесь в атмосферу уюта, окруженную живописными пейзажами и ароматом морского бриза. Здесь каждый найдет отдых по вкусу: от спокойного релакса до активного приключения.
Наши отели оборудованы всем необходимым для вашего комфорта и удобства. Современные номера, просторные бассейны, высококачественный сервис – всё это ждёт вас в Туапсе в 2023 году. Мы предлагаем индивидуальный подход к каждому гостю и стараемся сделать ваш отдых незабвенным.
Я наконец решился окунуться в мир азарта и нашел прекрасный сайт caso-slots.com. Здесь представлены все популярные казино, а также список тех, где можно получить бонус на первый депозит. Жду не дождусь начала игры!
С началом здорового образа жизни я осознал, что мне необходимы шнековые соковыжималки. Спасибо ‘Все соки’ за их великолепное оборудование. Теперь я наслаждаюсь свежими и полезными соками каждый день. https://blender-bs5.ru/collection/shnekovye-sokovyzhimalki – Шнековые соковыжималки помогли мне в моём стремлении к здоровью!